一直以来对KMP算法理解的不是很透彻。看了左神的程序员代码面试指南后感觉基本明白了。
我们都知道KMP算法最重要的是next数组,next[i]的含义是在match[i]之前的字符串match[0..i-1]中,必须以match[i-1]结尾的后缀子串(不能包含match[0])与必须以match[0]开头的前缀子串(不能包含match[i-1])最大匹配长度是多少。比如match="aaaab",我们来求一下next[4],match[4]=='b',它之前的字符串为"aaaa",根据定义它的后缀子串和前缀子串的最大匹配为"aaa",所以next[4]=3.

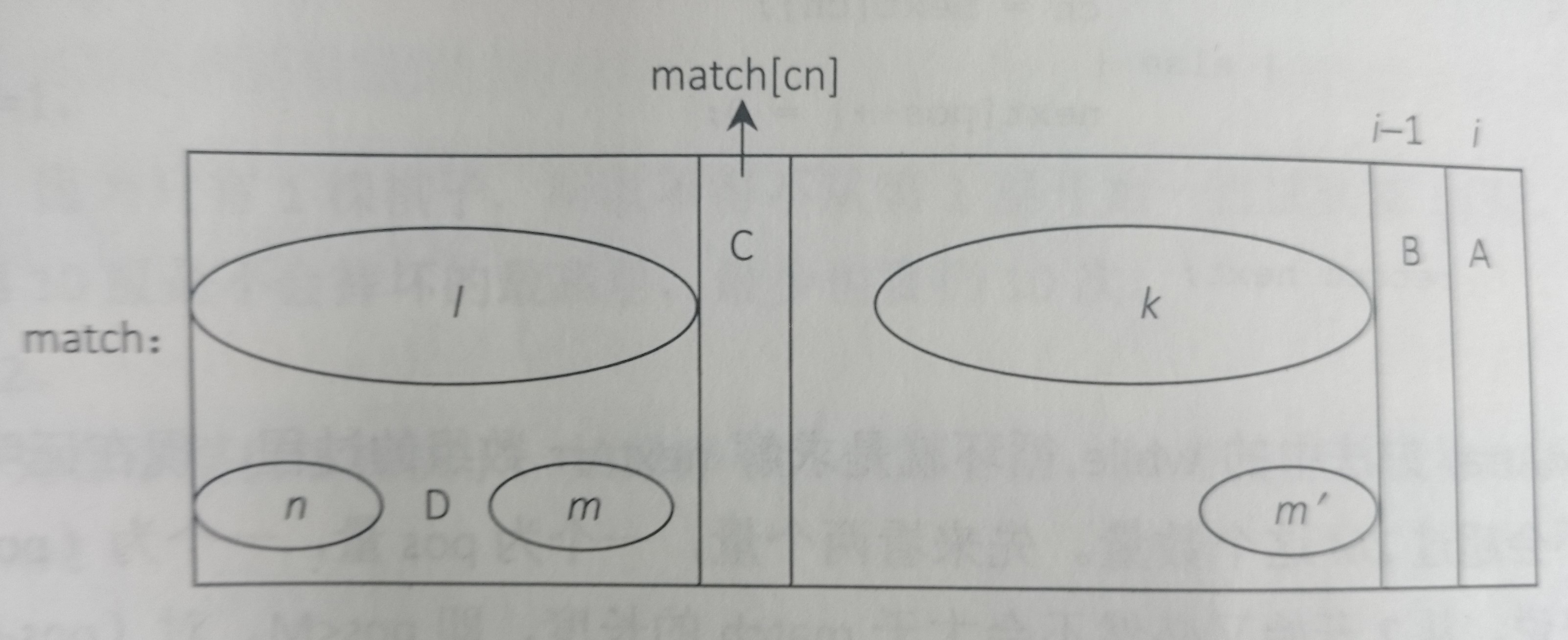
假设从str[i]出发,匹配到j位置时发现与match中的字符不一致,此时,我们利用next数组,next[j-i]表示match[0..j-i-1]这一段字符串前缀与后缀的最长匹配。假设前缀是a区域这一段,后缀是b区域这一段,再假设a区域的下一个字符是match[k],如图所示。

那么下次匹配时直接让str[j]与match[k]进行匹配。相当于match向右滑动。如果match滑到最后也没匹配出来,就说明str中没有match,为什么这样做是正确的呢?

如图,匹配到A字符和B字符才发生的不匹配,所以c区域等于b区域,有next数组可知b区域与a区域相等,所以直接把字符C滑到A的位置开始匹配即可,那么为什么中间这一段是不用检查的呢?
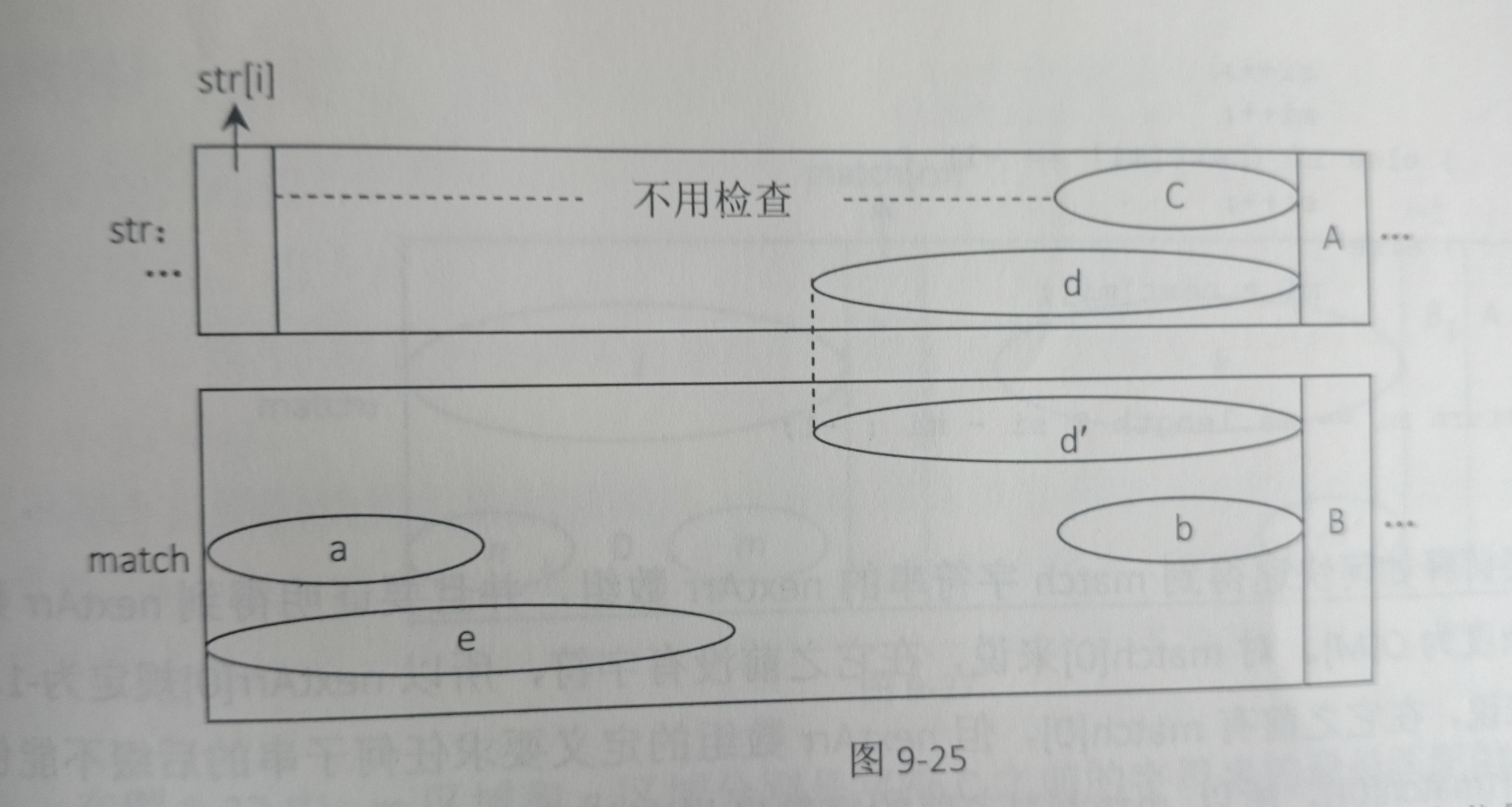
假设d区域开始的字符是不用检查区域的一个位置,如果从这个位置开始能够匹配出match,那么显然d区域和e区域相等,假设d区域对应到match中是d'区域,也就是字符B之前字符串的后缀,而e是match的前缀,随意对match来说,相当于找到了B字符之前字符串的一个比a,b区域更的大前缀与后缀匹配长度,这与next数组的值是自相矛盾的,因为next数组保存的就是最大前缀与后缀匹配长度,所以如果next数组的值计算正确,这种情况绝对不会发生。
匹配过程代码
int getIndexOf(string& s,string& m){ if(s.length()